Aprendizado de Máquina
Introdução
Imagine se um software pudesse aprender com suas próprias experiências, assim como um humano, e melhorar seu desempenho com o passar do tempo sem qualquer instrução explícita. Isso parece coisa de filme de ficção científica, certo? Por incrível que pareça, essa é a realidade do Aprendizado de Máquina (Machine Learning), uma fascinante subárea da Inteligência Artificial.
Esta tecnologia tem crescido exponencialmente, impulsionada por uma tempestade perfeita de avanços na capacidade de computação e a disponibilidade massiva de dados digitais. Assim como um recém-nascido começa a entender o mundo ao seu redor através de interações e experiências, um modelo de Machine Learning aprende a partir de grandes volumes de dados processados, identificando padrões e fazendo previsões.
Aprendizado de Máquina
Definição e conceitos básicos
Em sua essência, o Aprendizado de Máquina é o estudo de algoritmos e modelos estatísticos que permitem que um computador execute tarefas específicas sem o uso de instruções passo a passo. Em vez disso, esses sistemas confiam em padrões e inferências derivadas dos dados para realizar suas funções. Pense em como uma criança aprende a identificar um cão: ela não precisa que todos os cães do mundo sejam explicitamente apresentados a ela. Com o tempo, após ver várias imagens e interagir com diferentes cães, ela será capaz de reconhecer um cão, mesmo que nunca tenha visto aquele cão em particular. Esse é o princípio central do Aprendizado de Máquina.

Importância e aplicações do Aprendizado de Máquina
O Aprendizado de Máquina é mais do que apenas uma moda tecnológica - é uma ferramenta poderosa que já está transformando nosso mundo de maneiras surpreendentes. Imagine se conectar ao Netflix após um longo dia de trabalho, e a plataforma sugere um novo filme que é exatamente do seu gosto - essa é a mágica do Aprendizado de Máquina em ação.

E não é só isso. O Aprendizado de Máquina é a força por trás de uma miríade de outras aplicações que usamos diariamente: desde a assistente virtual em seu smartphone, capaz de entender e responder a suas solicitações verbais, até softwares de tradução automática que quebram barreiras linguísticas e facilitam a comunicação global.
Talvez um dos exemplos mais impressionantes de Aprendizado de Máquina seja o AlphaGo, o programa de computador que surpreendeu o mundo ao vencer o campeão mundial de Go, um jogo considerado muito mais complexo que o xadrez. Desenvolvido pela DeepMind, uma subsidiária do Google, o AlphaGo utilizou técnicas de aprendizado profundo para dominar este jogo milenar e demonstrar o poder e o potencial do Aprendizado de Máquina.

Tipos de Aprendizado de Máquina
Aprendizado Supervisionado
Pense no aprendizado supervisionado como um professor que orienta um aluno durante uma lição. O professor sabe a resposta certa e orienta o aluno até que ele também saiba a resposta. No contexto de aprendizado de máquina, o “professor” é um conjunto de dados rotulados - essencialmente, os exemplos que contêm o ‘problema’ (os dados de entrada) e a ‘resposta’ (o resultado desejado).
Por exemplo, se quisermos construir um sistema que seja capaz de identificar e-mails como ‘spam’ ou ‘não-spam’, forneceríamos ao modelo um conjunto de e-mails já rotulados como ‘spam’ ou ‘não-spam’. O modelo aprenderia os padrões associados a cada categoria e, com o tempo, seria capaz de classificar novos e-mails de maneira eficiente.
Aprendizado Não Supervisionado
O aprendizado não supervisionado, por outro lado, é como uma criança explorando um ambiente desconhecido sem qualquer orientação. A criança pode começar a notar padrões - por exemplo, objetos redondos tendem a rolar, objetos pontiagudos podem ser dolorosos ao toque, e assim por diante. Da mesma forma, no aprendizado não supervisionado, o modelo recebe um conjunto de dados não rotulados e precisa identificar os padrões e estruturas subjacentes por conta própria.
Por exemplo, um varejista online pode usar o aprendizado não supervisionado para segmentar seus clientes em diferentes grupos, com base em seus comportamentos de compra, preferências, histórico de navegação, etc. O modelo pode identificar padrões que humanos podem não perceber facilmente, proporcionando insights valiosos para o negócio.
Aprendizado por Reforço
O aprendizado por reforço é semelhante ao treinamento de um cachorro para aprender truques novos. Você dá ao cachorro uma recompensa quando ele faz a ação certa e possivelmente uma punição (ou ausência de recompensa) quando faz a ação errada. Com o tempo, o cachorro aprende a associar certas ações com recompensas positivas e evitar ações que resultam em punições.
No mundo do aprendizado de máquina, um dos exemplos mais notáveis de aprendizado por reforço é o AlphaGo, um programa de computador desenvolvido pela DeepMind que derrotou o campeão mundial do jogo de tabuleiro Go. O AlphaGo melhorou continuamente ao jogar milhares de jogos contra si mesmo, aprendendo com cada jogada e ajustando suas estratégias com base em recompensas e punições.
Classificação e Regressão
Na classificação, estamos interessados em prever uma resposta categórica. Por exemplo, um e-mail é ‘spam’ ou ‘não-spam’? No caso da regressão, estamos interessados em prever uma resposta contínua, que é tipicamente numérica. Por exemplo, qual será o preço de uma casa com base em suas características, como localização, número de quartos, tamanho, entre outros.
Extração de Características
Extração de características é como identificar os recursos mais notáveis ou distintos de algo para ajudar na sua identificação. Por exemplo, se quisermos diferenciar entre diferentes tipos de frutas, podemos usar características como cor, forma, textura e tamanho.
No contexto do aprendizado de máquina, a extração de características envolve identificar as variáveis mais relevantes nos dados que são mais úteis para prever a variável de interesse. Por exemplo, se estamos construindo um modelo para prever o preço de uma casa, as características poderiam incluir a localização da casa, seu tamanho, número de quartos, idade da casa e assim por diante.
Pré-processamento
Pré-processamento é como preparar os ingredientes antes de cozinhar. Você limpa, descasca, corta, e assim por diante. No contexto do aprendizado de máquina, o pré-processamento pode envolver várias etapas, como lidar com dados ausentes, normalização, padronização, codificação de variáveis categóricas, e assim por diante. O objetivo é transformar os dados brutos em uma forma que seja mais adequada e eficaz para os algoritmos de aprendizado de máquina.
Overfitting e Underfitting
Overfitting e underfitting são como vestir roupas que não se ajustam corretamente. Se uma roupa é muito apertada (overfitting), ela se ajusta demais aos contornos do seu corpo e pode ser desconfortável e restritiva. Se uma roupa é muito larga (underfitting), ela não se ajusta bem ao corpo e pode parecer desleixada.
No aprendizado de máquina, overfitting ocorre quando um modelo é excessivamente complexo e aprende tanto os padrões subjacentes quanto o ruído nos dados de treinamento. Embora possa ter um desempenho excelente nos dados de treinamento, ele geralmente terá um desempenho ruim em dados novos ou não vistos, pois não generaliza bem.
Por outro lado, underfitting ocorre quando um modelo é muito simples para capturar todos os padrões nos dados. Como resultado, ele pode ter um desempenho ruim tanto nos dados de treinamento quanto nos dados de teste.
Algoritmos de Aprendizado Supervisionado
K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) é como pedir recomendações a seus vizinhos mais próximos. Por exemplo, se você quiser saber se deve assistir a um novo filme, perguntaria aos seus vizinhos mais próximos (ou amigos) que têm gostos semelhantes aos seus. No aprendizado de máquina, o KNN é um algoritmo que classifica um item com base na classificação de seus “vizinhos” mais próximos no espaço de recursos. Aqui uma analise mais aprofundada: machine learning basics with the k-nearest neighbors algorithm
Modelos Lineares
Modelos Lineares são como a linha mais curta entre dois pontos. Eles tentam descrever uma relação linear entre as variáveis independentes (características) e a variável dependente (resultado). Um exemplo é a Regressão Linear, que é usada para prever um resultado contínuo, como o preço de uma casa com base em suas características. Outro exemplo é a Regressão Logística, usada para prever uma probabilidade que é então mapeada para duas ou mais categorias discretas, como ‘spam’ ou ‘não-spam’ para e-mails.
Classificadores Bayesianos
Os Classificadores Bayesianos são como um detetive que usa pistas e probabilidades para fazer deduções. Eles se baseiam no Teorema de Bayes, que é uma maneira de calcular a probabilidade condicional. Esses classificadores são muito úteis quando se tem uma quantidade limitada de dados ou quando se precisa considerar a incerteza dos eventos. Um exemplo popular de classificador bayesiano é o classificador Naive Bayes, que é comumente usado para classificação de texto, como na filtragem de spam.
Redes Neurais e Aprendizado Profundo
As Redes Neurais são como o cérebro humano, constituído por neurônios interconectados que trabalham juntos para aprender e tomar decisões. Assim como o cérebro humano usa sinapses para conectar neurônios, uma rede neural em aprendizado de máquina possui nós conectados que transmitem informações uns aos outros. As redes neurais profundas, uma subclasse do aprendizado profundo, têm várias camadas de nós, permitindo que elas aprendam representações complexas dos dados.
Um exemplo notável de redes neurais em ação é a tecnologia por trás do assistente virtual da Google, capaz de realizar tarefas como agendar compromissos ou fazer reservas em restaurantes, simulando a conversa humana de maneira convincente.
Explainable Artificial Intelligence (XAI)
Conceito e importância da explicabilidade
A inteligência artificial explicável, ou XAI, é como um professor transparente e aberto que não só fornece respostas, mas também explica como chegou a essas respostas. O campo da XAI visa tornar os modelos de aprendizado de máquina compreensíveis e justificáveis para os humanos. Isso é especialmente importante à medida que os modelos de aprendizado de máquina se tornam cada vez mais complexos e são usados em setores críticos, como saúde e justiça. A explicabilidade ajuda a construir confiança, facilita a detecção e correção de erros e atende a requisitos legais e éticos.
Técnicas de XAI
As técnicas de XAI são como ferramentas em uma caixa de ferramentas, cada uma com suas próprias forças e adequações para diferentes tarefas. Por exemplo, o LIME (Local Interpretable Model-agnostic Explanations) é uma técnica que tenta explicar as previsões individuais de qualquer classificador ou regressor de maneira compreensível e fiel. Ele faz isso criando uma aproximação local que é fácil de entender perto da previsão que está sendo explicada.
Outra técnica é a Anchors, que fornece regras de decisão de alto nível que “ancoram” a previsão com condições suficientes. Por exemplo, uma regra de ancoragem para um modelo de crédito poderia ser: “Se o rendimento anual do requerente é superior a 50.000 e ele não teve atrasos de pagamento nos últimos seis meses, o pedido de crédito será aprovado”.
Ambas as técnicas fornecem visões diferentes e complementares sobre como um modelo de aprendizado de máquina toma suas decisões e podem ajudar os humanos a compreender melhor e confiar nos modelos. Nesse post pode-se aprofundar mais no topico: Explainable Artificial Intelligence (XAI).
Algoritmos de Aprendizado Não Supervisionado
K-means Clustering
O K-means Clustering é como organizar uma biblioteca. Imagine que você é o bibliotecário e tem uma grande quantidade de livros para organizar, mas não tem uma lista de categorias. O que você faz? Você começa a ler os títulos, talvez até os resumos, e começa a agrupar os livros que parecem ser semelhantes.
Em termos de aprendizado de máquina, o K-means é um algoritmo que agrupa um conjunto de dados de n dimensões em k grupos distintos com base em seus atributos. Os grupos, ou “clusters”, são formados de tal forma que os dados em um cluster são mais semelhantes entre si (com base em alguma medida de distância) do que com os dados em outros clusters. Leia mais sobre K-means Clustering aqui.
Self-Organized Maps (SOM)
Os Mapas Auto-Organizáveis (SOM) são como uma festa onde as pessoas tendem a se agrupar com base em interesses comuns. Imagine uma grande sala com cientistas, artistas, músicos e atletas. Apesar de inicialmente espalhados, à medida que as conversas se desenvolvem, é provável que os cientistas acabem se agrupando, assim como os artistas, os músicos e os atletas.
No contexto do aprendizado de máquina, os SOMs são uma técnica de aprendizado não supervisionado usada para produzir uma representação de baixa dimensão (tipicamente bidimensional) dos dados de entrada de alta dimensão, preservando as propriedades topológicas. Em outras palavras, eles reduzem a complexidade dos dados mantendo as relações importantes. Isso é particularmente útil para a visualização de dados de alta dimensão. Leia mais sobre SOM aqui.
Aprendizado por Reforço
O aprendizado por reforço é como aprender a jogar um jogo de video game. No início, você não sabe como controlar seu personagem, quais ações levarão a quais resultados e quais movimentos resultarão na maior pontuação. Com o tempo e através de tentativas e erros, você começa a entender as regras do jogo e melhora sua performance. Leia mais sobre aprendizado por reforço aqui.
Q-Learning
Q-Learning é como se, depois de jogar várias partidas do jogo, você começasse a anotar as ações que levaram a melhores resultados. Essas notas são o que chamamos de função Q. No aprendizado de máquina, o Q-Learning é uma técnica dentro do aprendizado por reforço que procura aprender a política que maximiza a recompensa total esperada.
Uma aplicação real do Q-Learning é o sistema de navegação autônoma do Google DeepMind, que utiliza esta técnica para ensinar a agentes virtuais a navegar em ambientes complexos. Leia mais sobre Q-Learning aqui.
Conceito de recompensa e exploração
A recompensa e a exploração são como um rato em um labirinto procurando por queijo. O rato explora o labirinto (exploração), e quando encontra o queijo, recebe uma recompensa. No aprendizado de máquina, a recompensa é o feedback que o algoritmo recebe para entender se a ação tomada foi boa ou ruim. A exploração se refere ao algoritmo experimentar várias ações para entender qual delas leva à maior recompensa.

Um equilíbrio entre a exploração (procurar novas ações) e a exploração (repetir ações que já sabemos que são boas) é crucial para garantir que o algoritmo não fique preso em uma solução subótima ou passe muito tempo procurando pela ação perfeita.
Discussões
Funções de Ativação Novas e Onde São Aplicadas
As funções de ativação são importantes para determinar se e em que medida um neurônio deve ser ativado. As funções de ativação clássicas incluem a função Sigmoid, ReLU (Rectified Linear Unit) e Tanh. No entanto, novas funções de ativação estão sendo desenvolvidas para lidar com problemas associados a essas funções de ativação clássicas. Um exemplo é a função Swish, introduzida pelo Google, que se mostrou mais eficiente do que ReLU em alguns casos. A função Swish é simplesmente f(x) = x * sigmoid(x), que é suave e não saturada.
Buscar Algoritmos de XAI (Pintar Zonas que Pesaram Mais para o Processamento)
XAI (Explainable Artificial Intelligence) é um conjunto de processos e métodos que permite aos usuários humanos compreender e confiar nos resultados e na saída gerados por algoritmos de machine learning. A XAI é usada para descrever um modelo de IA, seu impacto esperado e os possíveis vieses. Ajuda a caracterizar a precisão, a imparcialidade, a transparência e os resultados dos modelos na tomada de decisões baseada em IA. A XAI avançou de tal forma que agora existem algoritmos capazes de indicar quais partes de uma imagem, por exemplo, contribuíram mais para uma determinada decisão. Um exemplo disso é a técnica Grad-CAM, que gera “mapas de calor” para indicar quais regiões da imagem foram mais relevantes para a decisão do modelo.
Contribuições Adicionais Acerca do Tema
O aprendizado de máquina tem uma série de aplicações práticas que estão transformando o mundo, desde carros autônomos até diagnósticos médicos. No entanto, também levanta questões éticas e de privacidade. Por exemplo, os algoritmos de aprendizado de máquina são muitas vezes “caixas-pretas” que tomam decisões que os humanos não conseguem entender, o que pode ser problemático em contextos como o sistema jurídico ou a medicina. Você pode ler mais sobre isso aqui.
Algoritmos e Técnicas não Discutidos em Sala
Um exemplo de técnica não discutida em sala é a Análise de Componentes Principais (PCA). A PCA é uma técnica de análise multivariada que pode ser usada para analisar inter-relações entre um grande número de variáveis e explicar essas variáveis em termos de suas dimensões inerentes (Componentes). O objetivo é encontrar um meio de condensar a informação contida em várias variáveis originais em um conjunto menor de variáveis estatísticas (componentes) com uma perda mínima de informação.
Técnica para Escolha de Número de Neurônios, Número de Camadas, Funções de Transferência
A escolha do número de neurônios, número de camadas e funções de transferência é mais uma arte do que uma ciência. Existem algumas regras práticas, como ter um número de neurônios ocultos entre o tamanho da entrada e o tamanho da saída, mas em última análise, depende muito do problema específico. Uma abordagem comum é começar com uma arquitetura simples e ir aumentando a complexidade (adicionando camadas/neurônios) até que o modelo comece a sobreajustar os dados. A validação cruzada também pode ser usada para selecionar a melhor arquitetura. Para mais detalhes, você pode ler este artigo.
Projetos e Problemas
Aqui estão alguns projetos e problemas que podem ajudar a aprofundar a compreensão e a aplicação prática dos conceitos de aprendizado de máquina.
Classificador de Spam de E-mail
Construir um classificador de spam de e-mail é um excelente projeto para começar com o aprendizado supervisionado. O objetivo é treinar um modelo usando um conjunto de e-mails rotulados como “spam” ou “não spam” e, em seguida, testar a eficácia do modelo na classificação de e-mails novos e não vistos.
Etapa 1: Importação das bibliotecas necessárias
Primeiro, vamos importar todas as bibliotecas necessárias. Precisamos do Pandas para carregar e manipular os dados, do Scikit-Learn para construir o modelo e avaliá-lo, e do Numpy para cálculos numéricos.
1
2
3
4
5
6
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import svm
from sklearn.metrics import confusion_matrix, classification_report
Etapa 2: Carregando e visualizando os dados
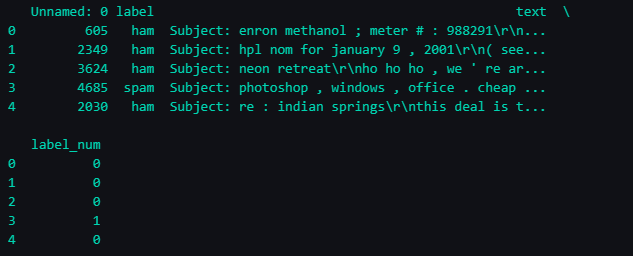
Vamos carregar os dados do arquivo spam.csv que você baixou do Kaggle. Este arquivo contém três colunas: text, label e label_num. A coluna text contém o texto do e-mail, a coluna label contém um rótulo indicando se o e-mail é spam (spam) ou não (ham), e a coluna label_num contém a representação numérica desses rótulos.
1
2
data = pd.read_csv('spam.csv')
print(data.head())
Output:
Etapa 3: Dividindo os dados
Agora, precisamos dividir nossos dados em conjuntos de treinamento e teste. O conjunto de treinamento é usado para treinar o algoritmo de aprendizado de máquina, enquanto o conjunto de teste é usado para avaliar a precisão do modelo.
1
2
3
4
X = data['text']
y = data['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Etapa 4: Convertendo texto em números
Os algoritmos de aprendizado de máquina trabalham com números, não com texto. Portanto, precisamos converter nosso texto em números. Para isso, usaremos a técnica chamada Bag of Words. Essa técnica transforma cada palavra distinta do texto em uma característica e conta o número de vezes que cada palavra aparece. Por exemplo, a frase “o céu é azul” seria transformada em algo como {'o': 1, 'céu': 1, 'é': 1, 'azul': 1}.
1
2
cv = CountVectorizer()
features = cv.fit_transform(X_train)
Etapa 5: Construindo o modelo
Agora, podemos usar esses recursos para treinar nosso modelo. Usaremos o classificador SVM (Support Vector Machine) para isso. O SVM é um tipo de algoritmo de aprendizado de máquina que tenta encontrar uma linha (em duas dimensões) ou um hiperplano (em mais de duas dimensões) que melhor divide os dados entre as duas classes. No nosso caso, o SVM tentará encontrar o hiperplano que melhor divide os e-mails entre spam e não-spam.
1
2
model = svm.SVC()
model.fit(features, y_train)
Etapa 6: Avaliando o modelo
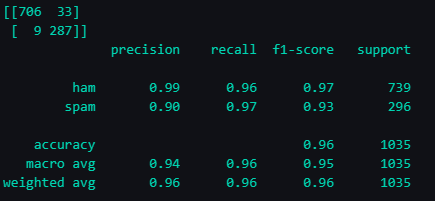
Finalmente, precisamos avaliar nosso modelo. Para isso, vamos transformar nosso conjunto de teste em números (como fizemos com o conjunto de treinamento) e fazer o modelo prever se cada e-mail é spam ou não. Em seguida, podemos comparar essas previsões com os rótulos reais.
A matriz de confusão é uma tabela que nos permite visualizar o desempenho do nosso algoritmo. Cada linha representa as instâncias da classe real e cada coluna representa as instâncias da classe prevista. Isso nos permitirá ver quantos e-mails foram classificados corretamente e incorretamente.
O relatório de classificação nos dará mais informações sobre o desempenho do nosso modelo, como precisão, recall e pontuação F1.
1
2
3
4
5
features_test = cv.transform(X_test)
predictions = model.predict(features_test)
print(confusion_matrix(y_test, predictions))
print(classification_report(y_test, predictions))
Output:
O arquivo em notebook esta localizado em: Classificador de Spam de E-mail
XAI: Explicando Modelos de Aprendizado de Máquina com Python e LIME
Neste tutorial, demonstraremos como visualizar e entender as decisões de um modelo de aprendizado de máquina usando a técnica de XAI (Explicabilidade em Inteligência Artificial) conhecida como LIME (Local Interpretable Model-agnostic Explanations). Utilizaremos uma imagem como entrada e um modelo pré-treinado (VGG16) para classificar essa imagem. Em seguida, aplicaremos o LIME para entender quais partes da imagem foram mais importantes para a decisão do modelo. No exemplo usamos a imagem de um gato.
Passo 1: Instalação das bibliotecas necessárias
Primeiro, instale as bibliotecas necessárias usando pip:
1
%pip install tensorflow numpy keras lime
Passo 2: Importação das bibliotecas necessárias
Importe as bibliotecas que vamos usar:
1
2
3
4
5
6
7
import numpy as np
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
from keras.preprocessing import image
from lime import lime_image
from skimage.io import imread
import matplotlib.pyplot as plt
from skimage.segmentation import mark_boundaries
Passo 3: Carregar o modelo
Carregamos o modelo que queremos explicar. Para este exemplo, usamos o modelo VGG16 pré-treinado do Keras.
1
model = VGG16(weights='imagenet', include_top=True)
Passo 4: Carregar e pré-processar a imagem
Aqui, carregamos a imagem que queremos classificar e pré-processamos ela para uso com o modelo VGG16.
1
2
3
4
5
6
7
8
def load_image(img_path):
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return x
img = load_image('path_to_your_image.jpg')
Passo 5: Fazer uma previsão com o modelo
Agora, fazemos uma previsão usando o modelo:
1
preds = model.predict(img)
Passo 6: Criar um explicador LIME
Aqui, criamos um explicador LIME e usamo-lo para obter uma explicação para a classificação da nossa imagem:
1
2
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(img[0], model.predict, top_labels=5, hide_color=0, num_samples=1000)
Passo 7: Visualizar a explicação
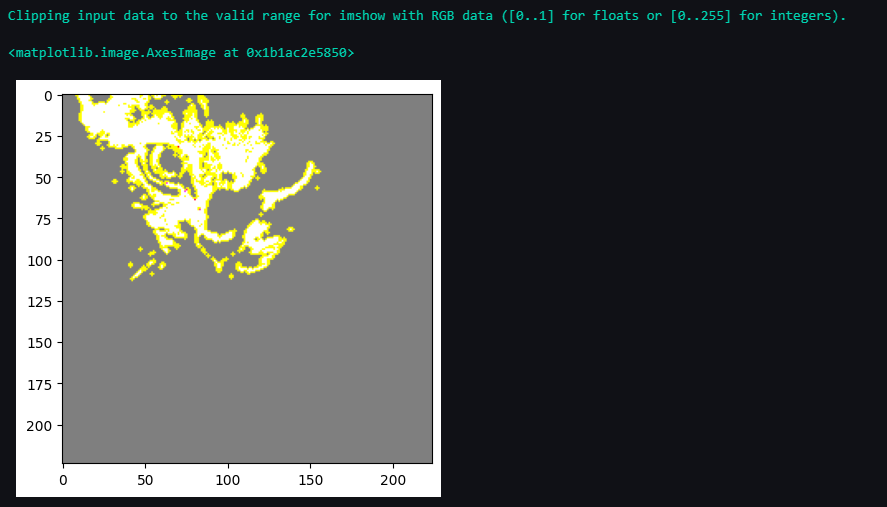
Por fim, visualizamos a explicação. Isso vai criar um mapa de calor mostrando quais partes da imagem foram mais importantes para a classificação:
1
2
temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=True)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))
Output:
Passo 8: Decodificar as previsões
Para ver quais objetos o modelo acha que são mais prováveis, podemos decodificar as previsões:
1
print('Predicted:', decode_predictions(preds, top=3)[0])
Output:

O arquivo em notebook esta localizado em: XAI exemplo verificar imagem de gato
Conclusão
Concluindo essa etapa de estudo sobre Aprendizado de Máquina, gostaria de fazer um resumo do que aprendi e compartilhar algumas reflexões.
Aprendizado
Aprendizado de Máquina: Não é só sobre algoritmos ou códigos, é um jeito revolucionário de entender o mundo e resolver problemas. Classificar emails, fazer um carro andar sozinho, e muito mais. A máquina ‘aprendendo’ pode fazer uma diferença incrível.
Tipos de Aprendizado: Temos várias abordagens - supervisionado, não supervisionado e por reforço - e cada uma tem suas forças e fraquezas. É uma caixa de ferramentas cheia de opções.
XAI: Explicabilidade em IA é vital. À medida que avançamos num futuro mais dominado pela IA, não podemos deixar de lado a transparência e explicabilidade dos nossos modelos.
Reflexão
Aprendizado de Máquina é um mundo de possibilidades. Mas, como todo grande poder, vem com grandes responsabilidades, como os desafios éticos e de privacidade.
Alertas
É preciso ter cuidado ao escolher e aplicar algoritmos de Aprendizado de Máquina. Cada escolha que fazemos afeta os resultados.
Preocupações
É importante entender o que estamos fazendo. Se não tivermos uma boa base teórica, podemos acabar com resultados que não fazem sentido. E também, não podemos esquecer de considerar as questões éticas e a necessidade de tornar nossos modelos transparentes e explicáveis.
Considerações Finais
Esse portfólio foi muito importante no meu estudo sobre Aprendizado de Máquina, ele mostra o que aprendi, os desafios que enfrentei e as perguntas que ainda quero responder. Agora é hora de levar o que aprendi para o mundo real e praticar mais!
Referências
- NORVIG, P.; RUSSELL, S., Inteligência artificial: Tradução da 3a Edição, [s.l.]: Elsevier Brasil, 2014.
- JAMES, G.; WITTEN, D.; HASTIE, T.; TIBSHIRANI, R. An introduction to statistical learning. New York: Springer, 2013.
- HASTIE, T.; TIBSHIRANI, R.; FRIEDMAN, J. The elements of statistical learning: data mining, inference, and prediction. New York: Springer, 2009.
- GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep learning. Cambridge: MIT Press, 2016.
- SUTTON, R. S.; BARTO, A. G. Reinforcement learning: An introduction. Cambridge: MIT Press, 2018.
- DOSHI-VELEZ, F.; KIM, B. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608, 2017.
- MOLNAR, C. Interpretable machine learning. Raleigh: Lulu.com, 2020.
- CHOLLET, F. Deep Learning with Python. New York: Manning Publications Co., 2017.
- DEEPMIND. AlphaGo - The Movie Full Documentary. YouTube, 2017.
- AIEDUCATOR894. Explainable Artificial Intelligence (XAI). Medium, 2023.
- RASCHKA, S.; MIRJALILI, V. Python Machine Learning: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2. Birmingham: Packt Publishing, 2019.
- Slides do professor e material de aula.